One of my prior posts looked into the intricacies of how Google/Deepmind went about creating one of the most dominant and versatile chess AI’s in the world. That inspired me to create my own version.
For any of you who are interested in the hard code please visit my Git Repo: ShallowMind Please feel free to reach out to me with any questions or observations, I’d truly love to hear any feedback you might have.
Intro –
The project name ShallowMind might seem like a derogatory offshoot of Deepmind, but it provides a glimmer of insight for the goal of the project. While the most dominant chess engines utilize Reinforcement Neural Networks and Alpha-Beta tree searches, I wanted to steer away from the hypothetical rabbit hole of evaluating countless permutations of moves. Instead, I explored an alternative that, if successful, could exponentially improve the evaluation efficiency while retaining the quality of evaluation.
The Process –
Without explicitly defining rules and restrictions, how do you teach a computer to play chess? When you compare it to how a human plays the game it becomes simple. A human will play a move that will provide the most advantageous position, or at least what they think is the most advantageous… Well, how do you evaluate how good a position is? This open-ended question is where you hit a roadblock since there is no deterministic way to win a game of chess. Getting an accurate evaluation of the game board is essential to choosing the best move from given a list of legal moves.
My approach, to this challenge involves incorporating Stockfish’s open chess engine for evaluating the positional value of the board, this will be my target variable for training my models. The features in the dataset will be the position of each piece arranged on a collection of 6 – 1×64 arrays, in bitwise format. This model will approximate Stockfish’s score without performing Alpha-Beta tree searches, which take a significant amount of time, as seen below – the deeper the evaluation the more nodes the tree search has to go through.
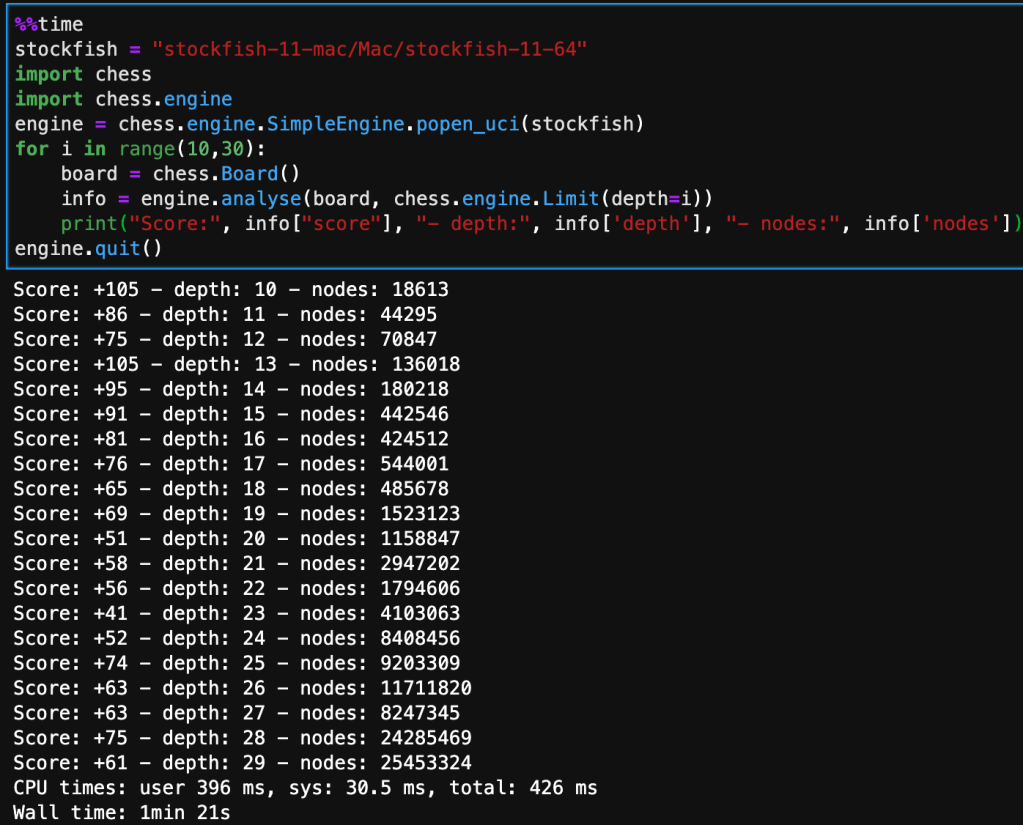
The board that’s being analyzed is the starting position from white’s perspective, so it is a very neutral board state.
The following code implements the same chess engine logic. It iterates and evaluates through a nested for-loop looking at each move inside each game, while converting the current position on the board to a bitwise state. Note that I limited the depth to 10 in order to collect enough data in the time constraint I was operating under. In the next run, I’m planning on increasing this to at least 15, maybe 20. Although this will significantly reduce the amount of data I can collect, it will increase the accuracy of Stockfish’s evaluation, and will have a direct improvement on the accuracy of my model. I will combine this methodology with another insight to optimize data selection for training my model.
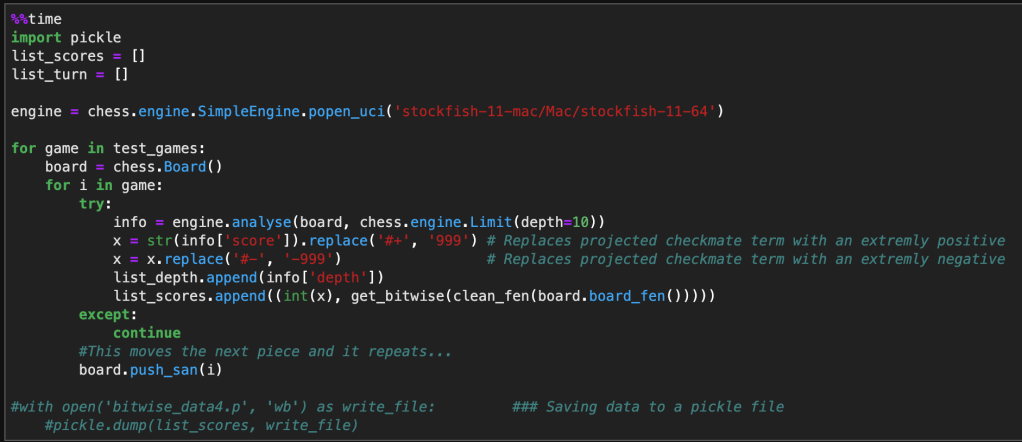
Below is a single sample of how a single board state evaluation looks like. The first value being the score evaluated by Stockfish and the 6 – 1×64 arrays correspond to the position of rooks, nights, bishops, queen, king, and pawns. The negative indicates a black piece and a positive indicates a white piece.
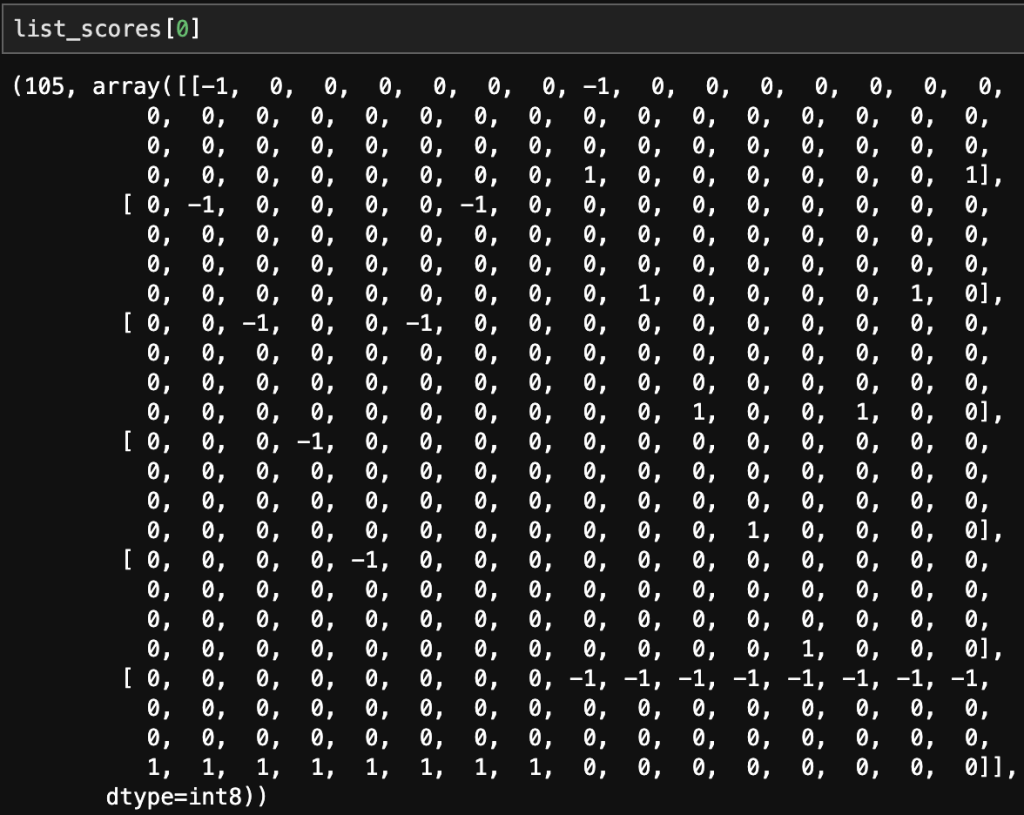
After doing data preparation and modeling, I occurred to me that the model was overfitting on neutral positions (between -1 and 1), this is problematic. When looking at the histogram of the evaluated scores, it became obvious that there was significant kurtosis. In order to improve the model I would need to under sample the neutral moves to place greater emphasis on the good/bad positions.
However, when you reduce the dominant class the amount of data at your disposal will drastically reduce the number of data points at your disposal. Combined with the bottleneck of data creation (through StockFish), I will have to create a nuanced approach to selectively chooses moves that mostly correspond to good or bad moves.
After creating the model on a subset of the better quality moves there was an increase in the evaluation error, but the model didn’t overfit. It also appeared to begin to understand each pieces movement, but would get lost in the dimensionality and still make blunders that would be obvious to a chess novice.
Endword –
This project appears to have no end in sight, but through the troubleshooting process, I am gaining a considerable amount of insight into how AI learns and process information. As well as how programs can be integrated with Python to further enhance the capabilities of the language.
Future Steps –
- Data Collection Process –
- Undersample the dominant class – neutral chess positions
- Increase the StockFish evaluation depth
- Feature Engineering
- Explicitly include quantity of pieces
- Hopefully this will emphasize the importance losing and capturing pieces
- Explicitly include quantity of pieces
