History/Predecessor:
Created by DeepMind, who were bought by Google in 2014, AlphaZero is child of the explosive popularity of AI, the desire to create the ultimate chess engine, and raw computing power. The creators, inspired to create a versatile AI that would dominate chess, Go, and Shogi. The premise being that they would only bound by the potential of AI, the rules of the game, and having no training on the moves of human opponents. To accomplish this, they trained for 24 hours on 5,000 tensor processing units, that were specifically developed for neural network learning. From those generated games they utilized Monte Carlo simulations that would score the results of sequential moves, and generate a “reward” that would score the potential outcome of the move. This decision, regardless of how pivotal the move, completely alters the game. And would require a new permutation of moves. It has been calculated that the game tree complexity of chess to be 10^123, this number is larger than the number of atoms in the universe. Being able to select the best move through brute force takes an insane amount of computational power. By training AlphaZero through Monte Carlo simulations, it reduces the number of computations down to 80,000 moves per second which is a fraction of the 70 million that Stockfish requires, arguably the most competitive engine next to AlphaZero. In spite of the computation deficiency, Alpha evaluates its position better and routinely beats StockFish When attempting to level the competition by reducing the amount of time for Alpha, it was only when Stockfish had 30 times the amount of time per move that Stockfish started to excel.
In regards to it’s versatility, not only has Alpha outperformed the best chess players and engines, it has also out performed similar type games Go and Shogi. Although Alpha carries the crown for the ultimate Chess AI, Deepmind wanted to create an AI that would excel in a plethora of board games and basic video games. This new AI would be called MuZero, while its not the main focus of this blog, it is astonishing that such a versatile AI could be made to nearly master a large amount of games.
The Engine Under the Hood:
What makes AlphaZero so good? DeepMind restricted the learning of the Alpha to only legal moves and only allowed it to train on its own simulated games. Both of these parameters penalized the training process by not allowing it to learn opening moves, and greatly increased the computational expense.
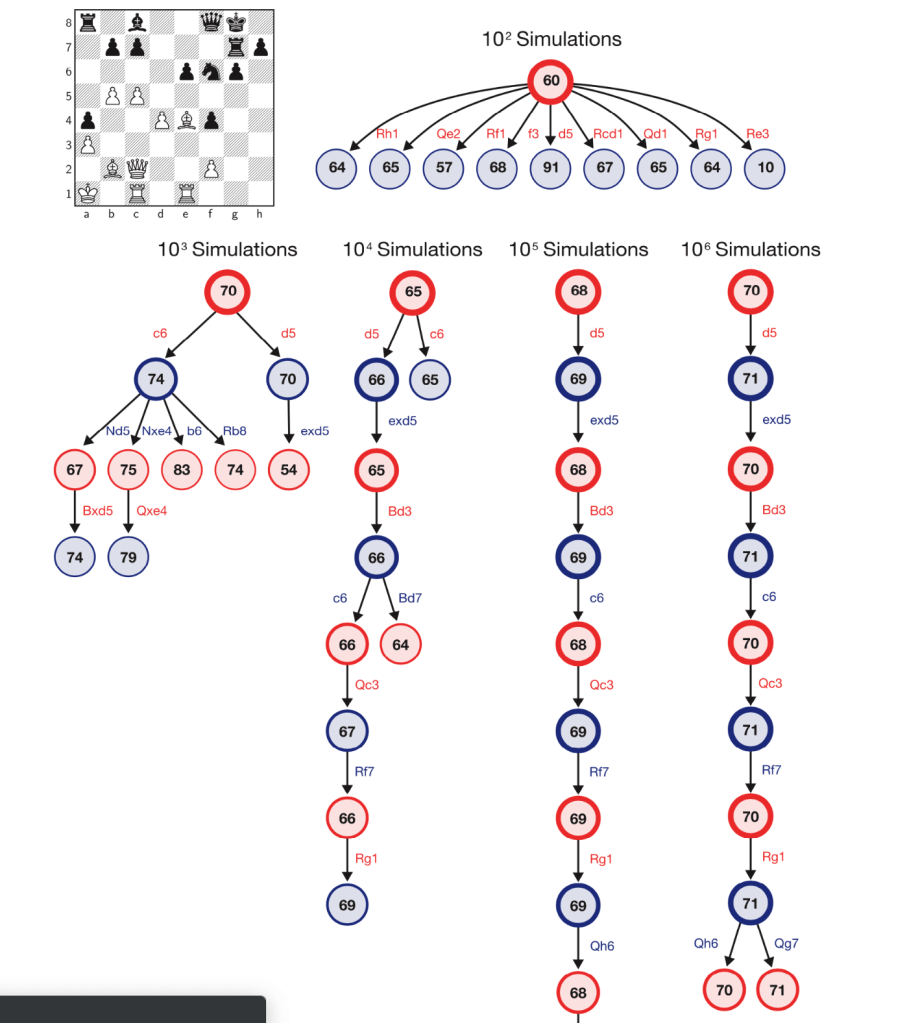
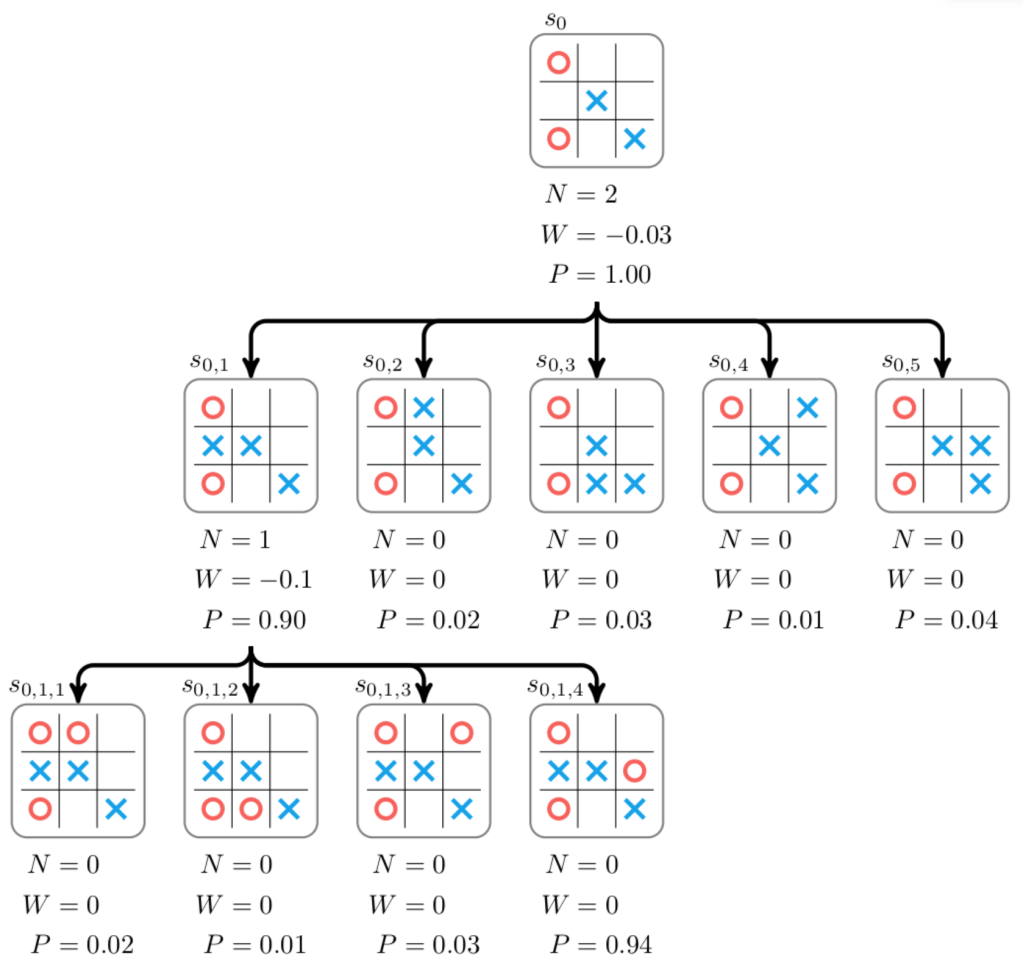
Monte Carlo Tree Search:
Through reinforcement learning, the AI will generate all possible moves and generate a score on how advantageous the move is. It will then branch out and continue downward on the tree evaluating each move at the next state. This process repeats until the AI reaches its defined limit or reaches the desired state, a win. At this point the program retraces its steps and reevaluates the assigned scores at each state, and selects which move to make based on how to reach the best score.

How Does it Evaluate Position?
Not sure. However, I’m sure it is proprietary. Another highly competitive engine, Stockfish, is an open-source project that we’re able to take a closer look. From http://rin.io/chess-engine/, the author outlines the criteria for evaluating each positional instance.

http://rin.io/chess-engine/
Reception:
Being able to evaluate such a long string of moves gives AlphaZero a unique play style that befuddles event the most accomplished chess players. A quote from Garry Kasparov, one of the best chess players of all time, best describes the nuances that make Alpha so special.
Programs usually reflect priorities and prejudices of programmers, but because AlphaZero programs itself, I would say that its style reflects the truth. This superior understanding allowed it to outclass the world’s top traditional program [Stockfish] despite calculating far fewer positions per second. It’s the embodiment of the cliché, “work smarter, not harder.”
AlphaZero shows us that machines can be the experts, not merely expert tools. Explainability is still an issue—it’s not going to put chess coaches out of business just yet. But the knowledge it generates is information we can all learn from. Alpha-Zero is surpassing us in a profound and useful way, a model that may be duplicated on any other task or field where virtual knowledge can be generated.