In the theme of expanding my data science toolbox, in this blog I will be exploring a few products, provided by Amazon, that are commonly used in data science.
Why AWS Products?
At the time of writing this, I had recently gone on a tour of company that conduct large scale data exploration and I got an overview of how data moves throughout the company. I felt a little overwhelmed by the list of products they used and how they were related and how they fabricated insights through this pipeline. After wrapping my head around this schema, I noticed that a significant number of the products were provided by AWS, and realized that this wasn’t going to be the last time that I would see them.
AWS currently offers 175 cloud based services, geared towards all different cloud based services that a company could want. I just wanted to pick and choose a few that seemed applicable, and become familiar with their functionality. As well as a couple that peeked my intrest.
The Products
- Amazon Simple Storage Service (S3)
- AWS Glue (ETL)
- Amazon Athena
- Amazon Redshift
- Amazon Timestream
- Amazon Aurora
- Amazon RDS
Amazon Simple Storage Service (S3)
One of the more straight forward products Amazon offers. It can be comprised of both structured and unstructured data, the later is more common. It’s primary use is as storage space for your companies data lake, and is essentially a highly-scalable cloud storage platform with a focus towards interactivity between other AWS products. Such as security products like AWS CloudTrail or data warehousing products like; Redshift, RDS, or Aurora. There are a few different variants that cater to the particular needs that companies face, like S3 glacier. Which is an archive service with lower cost, but comes at the expense of response time, ranging from minutes to multiple hours. The items stored on S3 are referred to as objects and are limited to 5TB or less per object. You can access the objects through REST API, Software Dev Kits, or other Amazon query methods. In our daily lives as a data scientist, S3 will most commonly be a source of collecting data. It could be in a raw form that requires coercing to get usable data for analytics, but more often than not, companies won’t want to waste space on unnecessary data. Depending on the size of the company and frequency of the data pull, this data could have already been formatted, and inputed into some sort of database.
AWS Glue
AWS Glue is an extract, transform, and load (ETL) tool that enables us to more effectively pick out and homogenize data across multiple AWS services using metadata. By doing so it allows us to query and analyze new data much more efficiently. The illustration below, from AWS does a good job showing how new data in your S3 data lake can be seamlessly merged with existing data in a relational database to yield refined data that is ready for further preparation and analysis in Redshift and other utilities.
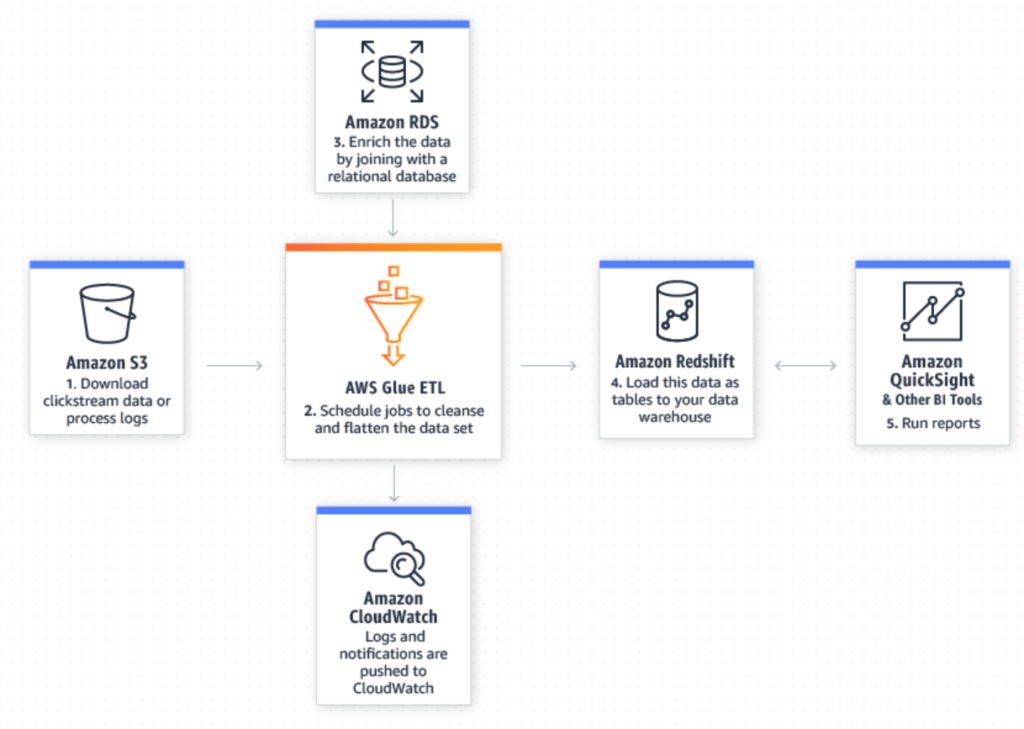
Amazon Athena
Amazon Athena is a SQL query tool for S3. Because of that, it’s arguably the easiest way to explore data inside of S3. The best fit for this tool lies in ad-hoc queries, but when combined with AWS Glue, we’re able to enrich the S3 data with other sources to reach meaningful conclusions using simple SQL queries and pumping it into Amazon QuickSight, Tableau, or other data interpretation tools.
Amazon Redshift
Amazon Redshift is a centralized repository for processing structured and unstructured data. This is where a bulk of our time is spent as data scientist. Then we can export it back to S3 for further analysis, or Amazon Quicksight to display your findings. One of the biggest advantages to utilizing a cloud computing platform like AWS is its ability to handle extremely large amounts data. Without it, our large queries and data processes would take an exhaustible amount of time, provided your computer doesn’t reject the request.
Amazon Timestream
Amazon Timestream is a unique database service that stores data in set time intervals. As an effect, it is optimized to run 1,000 times faster than conventional relational databases, and can process the new queries down to the nanosecond frequency. Real life data is always developing and fractional seconds count. Being able to collect and analyze your data, and create actionable responses as efficiently as possible is extremely valuable. The article below from the Motley Fool outlines the lengths high-frequency traders went through to obtain 1-billionth of a second advantage over fellow traders.
https://www.fool.com/investing/general/2016/02/23/the-absurdity-of-what-investors-see-each-day.aspx
Amazon Aurora and Amazon RDS
Amazon RDS – Is a hosted database service that enables data exploration inside of Redshift. Amazon allows the customer to choose between these engines to run queries off of:
- PostgreSQL
- MySQL
- MariaDB
- Oracle
- Microsoft SQL Server
- Amazon Aurora
Amazon Aurora – Is a cloud based relational database engine that is 5x faster than standard mySQL queries, but maintains compatible with mySQL and PostgreSQL.
Realizations
Amazon offers a lot of products. A lot of those products seem to do similar things, but they all seem to have their niche in Amazon’s product line. As needs emerge for Amazon customers, it is evident that Amazon has the resources to evolve and incorporate this into existing products or develop an entirely new tool to deal with this need.
